| | | | | |
- Uxn -- Graphical emulator (), command-line emulator (), and assembler ().
- Dfriblim -- A native Uxn compiler.
- Beetbug -- A debugger.
- Uxnlin -- A linter.
- Uxnfor -- A formatter.
- Lef -- A native Uxn IDE.
- Uxn Opcodes - Uxntal opcode reference.
- Varvara - External I/O reference for Uxn.
Installation is fairly straightforward. The easiest method (in my opinion) is to visit the source-hut repository maintained by 100 Rabbits, then download and compile the emulator you want. I use on macOS, while might be the author’s preference. After compiling your chosen emulator, you can download and compile other tools (like ) the same way:
❯ ~/bin/uxnasm src/beetbug.tal beetbug.rom
-- Unused label: cursor
-- Unused label: cursor/x
-- Unused label: cursor/y
-- Unused label: emu
-- Unused label: uxn
-- Unused label: draw-bal
-- Unused label: dict
-- Unused label: push/8
-- Unused label: poke/8
-- Unused label: peek/8
-- Unused label: warp/8
-- Unused label: devw/8
-- Unused label: devr/8
-- Unused label: scrollbar-icn
-- Unused label: cap-icn
-- Unused label: controls-icns
Assembled beetbug.rom in 5595 bytes(8.57% used), 338 labels, 0 macros.
At this point, you have three particularly useful tools: the emulator, the assembler, and the debugger.
If you use on macOS, you might encounter the following warning:
uxncli(64788,0x1ff0b0240) malloc: nano zone abandoned due to inability to reserve vm space.
As suggested on Stack Overflow, setting the following environment variable typically fixes it:
export MallocNanoZone=0
At its core, Uxn is a virtual CPU, an idealized 6502, so some of its opcodes might look familiar to 8-bit veterans. Another nostalgic quirk is that Uxn programs start at memory offset , reminiscent of .COM files under DOS or CP/M.
Varvara is the name for the complete "computer" built around the Uxn CPU, encompassing devices for external I/O. You might see the terms "Uxn" and "Varvara" used interchangeably, but they differ conceptually.
Uxn is designed to be small. It has a 16-bit address bus, meaning base memory is 64 KiB. Emulators are encouraged to support 16 "banks" of memory (1 MiB total), although the specification allows up to 4 GiB of bank-switched memory in theory.
The Uxn system also provides four customizable colors, mouse and keyboard input, four-channel audio, and a display resolution of 512×320, which can scale up to 2048×2048 (at least in the reference emulator). Despite this minimalistic palette, many Uxn applications still look strikingly aesthetic, reminiscent of old black-and-white or 2-bit graphics.
Screenshot by author.
Left -- UXN developer environment
One design motivation behind Uxn is software sustainability and longevity. Devine Lu Linvega (the creator) aims for a platform that could feasibly run for 100+ years, one simple enough to be re-implemented on nearly any future hardware or environment. This stands in contrast to modern platforms that change constantly and lock you into complicated subscription models or online verifications.
For more background, consider Devine’s talks:
- A shining palace built upon the sand which may be taken down in a near future due to Handmade Con orgas going with the wave of anti-everything-human thats rolling through US recently,
- Weathering Software Winter,
- An approach to computing and sustainability inspired from permaculture,

Screenshot by author.
Oquonie -- UXN game
Tal (or Uxntal) is a "semi-assembly" language for the Uxn CPU. It mostly works like assembly but incorporates features such as lambdas. It’s also stack-based, making it feel like a cross between traditional assembly and Forth, where opcodes like and replace what might otherwise be high-level function calls.
This post focuses on the debugging and puzzle-solving process. For a deep dive into Varvara’s I/O design or the full Uxntal specification, see the official Uxntal documentation and the Varvara reference.
When learning a new language, I often skim the docs, attempt a small project, and iterate with the help of a debugger. Uxntal has a few unique twists:
- Stack-based operations sometimes cause confusion about byte vs. short usage.
- Conditional jumps come in two flavors: label-based (?&label) and lambda-based (?{ ... }).
- Self-modifying code is common as a technique to increment pointers or store data inline.
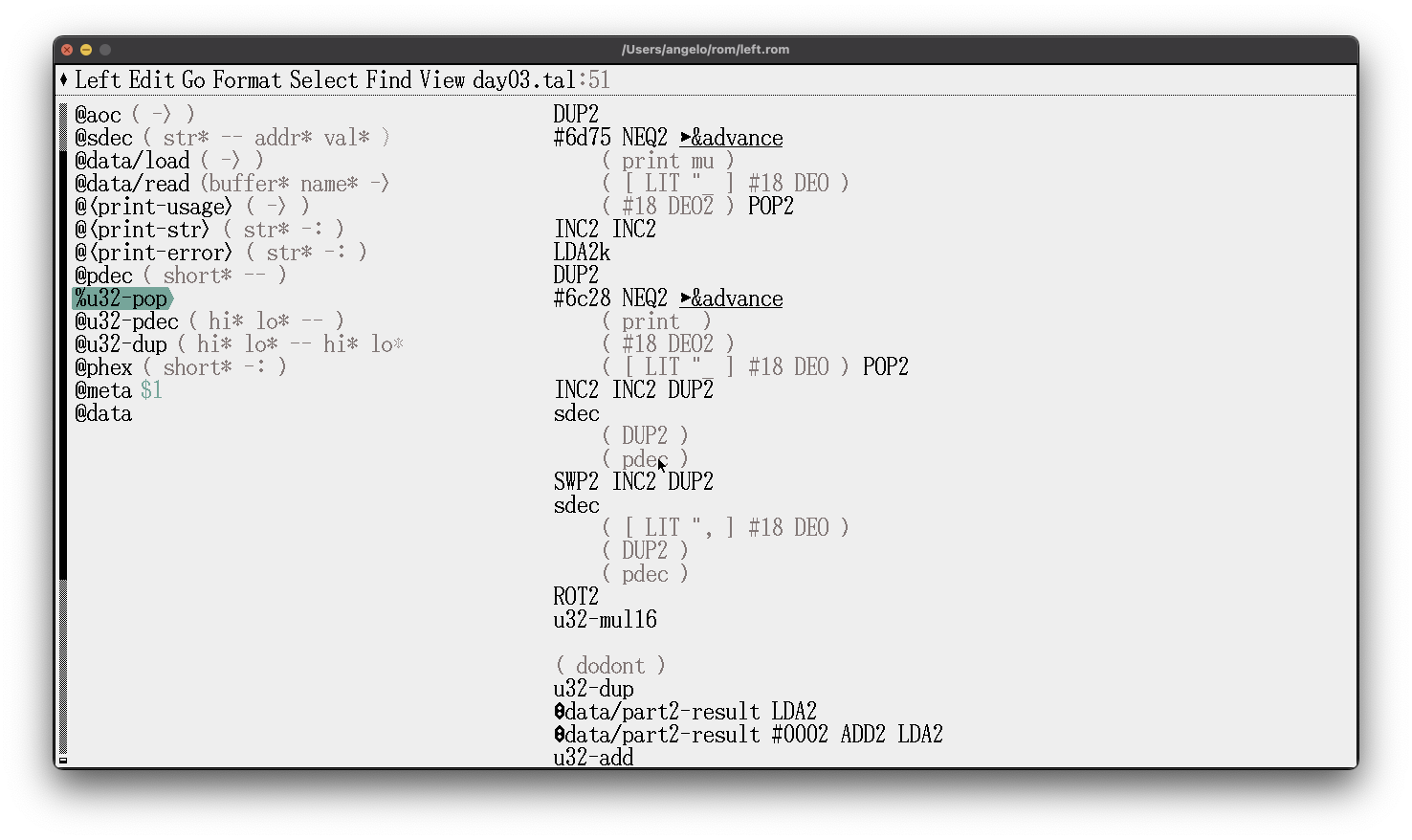
Below is a snippet from a standard library I studied to understand Uxntal better:
@pdec ( short* -- )
#000a SWP2 [ LITr ff ]
&>get ( -- )
SWP2k DIV2k MUL2 SUB2 STH
POP OVR2 DIV2 ORAk ?&>get
POP2 POP2
&>put ( -- )
STHr INCk ?{ POP JMP2r }
[ LIT "0 ] ADD #18 DEO !&>put
I wanted to understand how it worked, so I carefully tracked how the stack changed after each instruction (similar to what I once did with x87 math instructions):
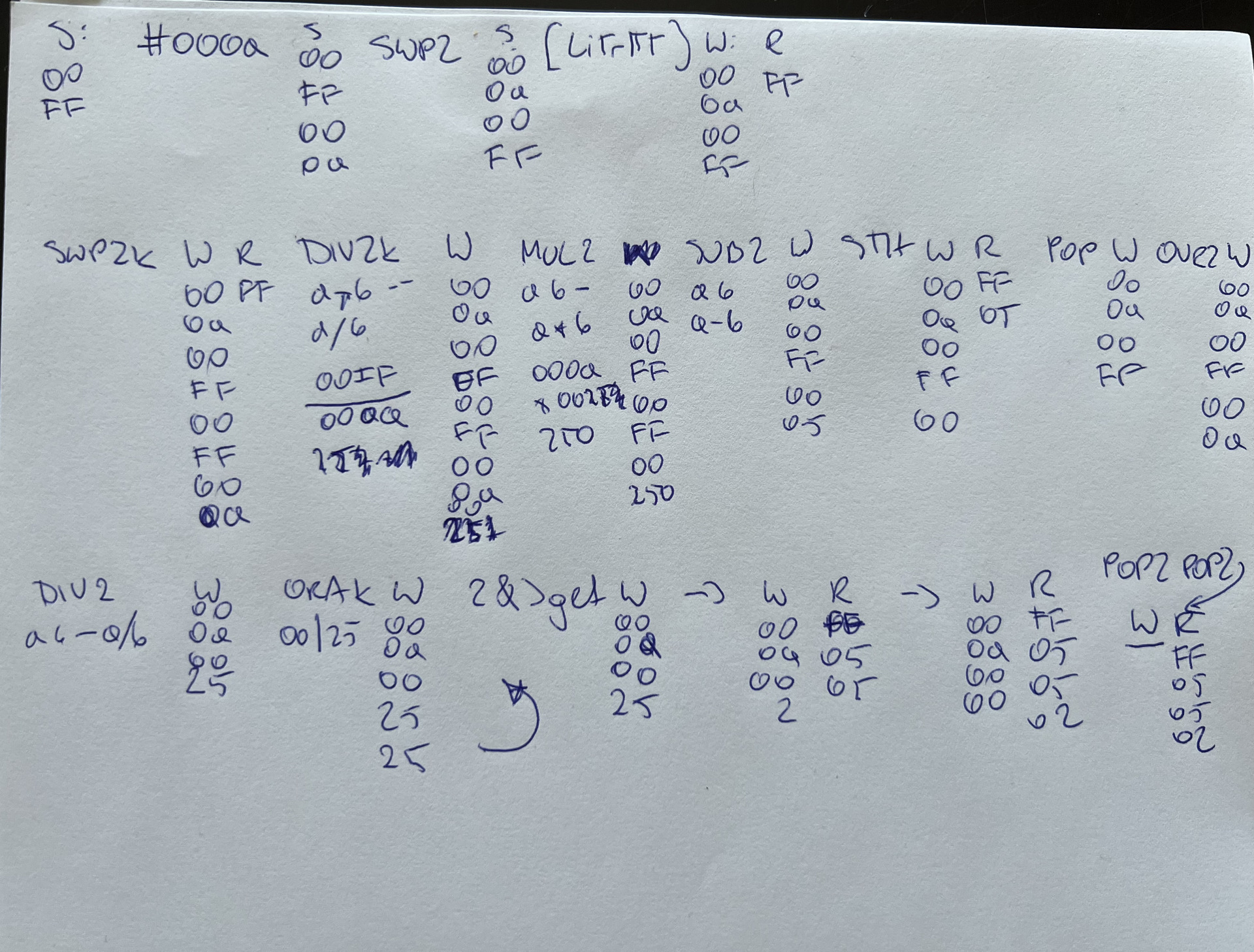
Photo by author.
Unroll all the loops! Show me the stack.
Later, Devine mentioned a much simpler technique for debugging: printing stack contents via . The official docs say:
Sending a non-null byte to the System/debug port will print the content of the stacks or pause the evaluation if the emulator includes a step-debugger.
Since Uxn debuggers (like ) currently don’t integrate with command-line parameters, calls () turned out to be the most convenient debug method. For instance:
%debug { #010e DEO #0a18 DEO }
@pdec ( short* -- )
#000a SWP2 [ LITr ff ]
&>get ( -- )
SWP2k DIV2k MUL2 SUB2 STH
POP OVR2 DIV2 ORAk ?&>get
debug
BRK
POP2 POP2
&>put ( -- )
STHr INCk ?{ POP JMP2r }
[ LIT "0 ] ADD #18 DEO !&>put
When running:
❯ ~/bin/uxnasm day03.tal day03.rom && ~/bin/uxncli day03.rom
Assembled day03.rom in 482 bytes(0.74% used), 61 labels, 2 macros.
WST 00 00 00 00 00 00 00|32 <
RST 00 00 00 00 00 00|02 00 <
I can see the stack changes at each debug. Usually, mistakes arise from forgetting to handle short vs. byte properly.
Another subtlety: there are two ways to do conditional jumps in Uxntal with the rune, either with labels or lambdas. Internally, emits the opcode:
JCI cond8 -- Pops a byte from the working stack and if it is not zero, moves the PC to a relative address at a distance equal to the next short in memory, otherwise moves PC+2. This opcode has no modes.
Consider this snippet:
|100 #0000
@>get
#01 ?>get POP2
|0100 #0000 ( a00000 )
|0103 #01 ( 8001 )
|0105 JCI ( 20 )
|0106 FFFB ( -4 )
|0108 POP2 ( 22 )
We push onto the stack, then checks if it’s nonzero. If it is, jump to the relative address in the next short to . If zero, skip past it. That’s logical enough.
But this snippet with lambdas behaves differently:
|100 #0000
@>put ( -- )
#01 ?{ POP BRK }
#0a#18 DEO !>put
Initially, I thought lambdas should be identical to label-based conditional jumps, where instead of I would get . But they're not. introduces a block that ends at , and the references the block’s end address. Visually, it can look odd, but it avoids the complexity of relocations

Photo by author.
Diassembled lambda
When you really think about it, it makes complete sense. Handling relocations that way would be difficult, and this approach lets Uxn provide higher-level features while still generating code whose layout directly reflects the source -- much like traditional assembly. Because points to the closing bracket (the end of the lambda), can jump in the non-zero case to whatever visually follows that lambda.
This design also reflects a key point Devine discusses in his presentations: modern tools often sacrifice performance for developer convenience. While this might not be the most pleasant developer experience, it keeps the opcode set minimal, removes the need for complex relocation, and yields compact binaries.
While working on a puzzle, I wanted to handle command-line parameters and read from a file specified in those parameters. Reading the file is straightforward:
|a0 @File &vector $2 &success $2 &stat $2 &delete $1
&append $1 &name $2 &length $2 &read $2 &write $2
|100
@data/read (buffer* name* -> )
.File/name DEO2
#4e20 .File/length DEO2
.File/read DEO2
.File/success DEI2
;data/file-size STA2
JMP2r
Reading arguments was a little trickier. Information about them and comes through the same mechanism in Uxn: the console subsystem vector. Vectors in Uxn behave much like interrupts—small routines that the host calls. To determine whether any parameters are available, you can check the console input port :
.Console/type DEI ?&has-args <print-usage> BRK
&has-args ( ... )
That port tells you the type of incoming data via port . The documentation is sparse, but it does mention:
The Console/vector* is evaluated when a byte is received. The Console/type port holds one of 5 known types: no-queue(0), stdin(1), argument(2), argument-spacer(3), argument-end(4).
In practice, this means:
- There is a single queue that merges command-line arguments and stdin. The emulator effectively concatenates them into one string.
- For each byte in that string, is triggered.
For example, running provides the uxn program with a concatenated string of and a corresponding sequence of type values like . I didn’t fully understood that until I read the emulator source code.
To handle arguments, you simply set up a function for the console interrupt:
;read-args .Console/vector DEO2
Then you can read and store each incoming byte:
@read-args ( -> )
#02 .Console/type DEI NEQ ?&is-arg-done
.Console/read DEI
[ LIT2 00 &ptr -arg ]
INCk ,&ptr STR STZ2
BRK
&is-arg-done
This snippet could be more flexible for edge cases, but it works for me. It uses two handy tricks:
- Self-modifying code A naive approach might look like:
.Console/read DEI ( read the byte from console )
-arg ( store buffer address )
STZ ( store byte in zero page )
The STZ instruction stores a byte at a given zero-page address. However, we also need to increment the pointer so the next interrupt stores the next byte at . That’s where self-modifying code helps. Instead of a fixed , we use:
[ LIT &ptr -arg ]
This creates a label (&ptr) referencing the exact memory that holds the LIT operand. Later, we can write:
#51 ,&ptr STR
which changes that operand from to . The next time the code runs, it effectively executes . On older 8-bit systems like the Atari XL/XE or C64, self-modifying code was common, but I hadn’t used it much until now.
- Ensuring a zero-terminated string. By using , we push a two-byte value onto the stack (e.g., for address ), and then will store at that address, guaranteeing a terminator. This way, every time we read a byte from , we also keep the string properly null-terminated.
With a better handle on the language, platform, and tools, I’m now ready to move on to the main part of the project.
To no surprise, I’m working on the 3rd day of Advent of Code this time. It doesn’t look too bad. I need to find occurrences and sum them up.
Here's what I came up with:
|100
@aoc ( -> )
;data/file-buffer ;data/buffer-ptr STA2 &loop ;data/buffer-ptr LDA2 LDA2k DUP2 #6d75
NEQ2 ?&advance
( print mu ) [ LIT "_ ] #18 DEO
#18 DEO2
INC2 INC2 LDA2k DUP2 #6c28 NEQ2 ?&advance
( print ) #18 DEO2 [ LIT "_ ] #18 DEO
INC2 INC2 DUP2 sdec SWP2 INC2 DUP2 sdec ROT2 MUL2 ;data/part1-result LDA2 ADD2 debug
;data/part1-result STA2 INC2 LDA2k &advance POP #18 DEO
INC2 DUP2 ;data/buffer-ptr STA2
LDA ?&loop
;data/part1-result LDA2 print-break print-break debug BRK
that small loop goes through the file’s contents byte by byte, fetches the next two characters, assumes they’re ASCII so I can compare them numerically, and means . In other words, I first catch the token, then the token. If I detect I parse the digits, move one byte forward to skip the comma, and parse the next set of digits.
That all worked fine for my test input, but when I ran it on , the result was wrong. Now what? Since I can’t easily use , and stack-dumping with would be painful given there are 720 mul operations in total, I decided to print all the muls I found and compare them with a list generated by an external script:
import re
regex = re.compile(r"mul\([0-9]+,[0-9]+\)")
file = open("input.txt", "r")
text = file.read()
for match in regex.findall(text):
print(match)
I discovered my code was too naive. It only checked for the start of the pattern, which allowed a few invalid entries, such as or . I needed to verify there was a after the digits. That also meant I couldn’t immediately calculate and store the product. Instead, I had to wait until I confirmed the pattern ended correctly. To do that, I temporarily hid the values on the return stack:
STH2
STH2
LDAk
#29 NEQ ?&skip-pop ( 29 is closing paren )
STH2r
STH2r
;data/part1-result #0002 ADD2 STA2
;data/part1-result STA2 &skip
( ... )
&skip-pop POP2r POP2r !&skip
I also realized I had incremented the pointer too soon after parsing the closing bracket, missing patterns like . That was a quick fix.
I ran it again:
Assembled day03.rom in 473 bytes(0.72% used), 64 labels, 2 macros.
loading file: input.txt
result part 1: 26926
and the answer was still incorrect. After inspecting the last few muls, I noticed alone yields , which is too large for a 16-bit value.
At that point, I was about ready to give up. I didn’t feel like implementing full 32-bit math myself on a Saturday evening. Fortunately, Devine pointed me to an excellent library that was already written. I only had to add a few minor helpers and a routine to print 32-bit numbers (the Uxn standard library only includes 16-bit decimal printing):
%u32-pop { POP2 POP2 }
@u32-pdec ( hi* lo* -- )
[ LITr ff ]
&>get ( -- )
#0000 #000a
u32-divmod
STHk
u32-pop
u32-dup
u32-non-zero ?&>get
u32-pop
&>put ( -- )
STHr INCk ?{ POP JMP2r }
[ LIT "0 ] ADD #18 DEO !&>put
@u32-dup ( hi* lo* -- hi* lo* hi* lo* )
STH2
DUP2
STH2r
DUP2
STH2
SWP2
STH2r
JMP2r
Let’s see:
Assembled day03.rom in 1343 bytes(2.06% used), 144 labels, 2 macros.
loading file: input.txt
result part 1: 184576302
Perfect! Now, on to part 2. Fortunately, part 2 is a minor modification of part 1, so I reused most of the code with only a few changes. I added support for detecting and , simplified by matching four bytes and then either or . I was lucky that part 2 didn’t have any tricky edge cases.
I inserted this snippet at the start of the loop:
DUP2
#646f ( do ) NEQ2 ?&parse-mul
POP2 INC2 INC2 LDA2k DUP2
#2829 ( open-paren close-paren ) NEQ2 ?&do-skip
( [ LIT "+ ] #18 DEO #0a18 DEO )
#01 ;data/dodont STA !&parse-mul
&do-skip
DUP2
#6e27 ( n' ) NEQ2 ?&parse-mul
( [ LIT "- ] #18 DEO #0a18 DEO )
#00 ;data/dodont STA
Then I set a variable depending on those tokens. Inside the loop, I added to the second result only if the variable was set:
;data/dodont LDA ?&store-do-result !&pop-do-result
&store-do-result
STH2r
STH2r
;data/part2-result #0002 ADD2 STA2
;data/part2-result STA2
( ... )
&pop-do-result POP2r POP2r !&skip
Final run:
Assembled day03.rom in 1476 bytes(2.26% used), 150 labels, 3 macros.
loading file: input.txt
result part 1: 184576302
result part 2: 118173507
The correct answer on the first try! After some practice, it definitely gets easier.
One interesting takeaway: adding 32-bit (u32) support increased the ROM size from bytes to bytes—nearly a jump.
The code is available on Codeberg as usual. It's pretty brute force, looses track of the stack in few places, and could definietely use some refactoring... my point is: Do not try this at home. Or at all.
You'll probably be better off learning from Rek & Devine, or from IRC crowd (#uxn @ Libera).
Till the next time!